
Have you ever seen a survey response like this?
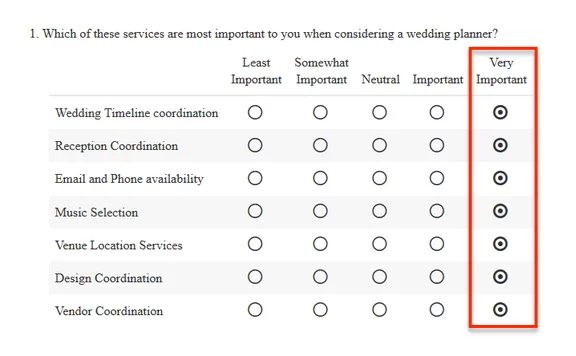
This type of response is referred to as straightlining. It occurs when respondents are in a hurry, or if they actually feel everything is important.
When respondents straightline their survey responses you get very little actionable data. This is where Maximum Differential Scaling, a.k.a. MaxDiff, can help.
Which is more important? Choose 1!
MaxDiff questions force respondents to rank the relative importance of services, brands or ideas, so that you don’t get unhelpful straightlining.
Maxdiff questions convey a simple task to the respondent:
Pick the best and worst attribute from the currently displayed options.
Sometimes you want to know your respondent’s preference and ranking for several items.
For example, If you’re a wedding planner, you might want to figure out which services that you offer are most important to your customers. You could use a radio button grid like this one:
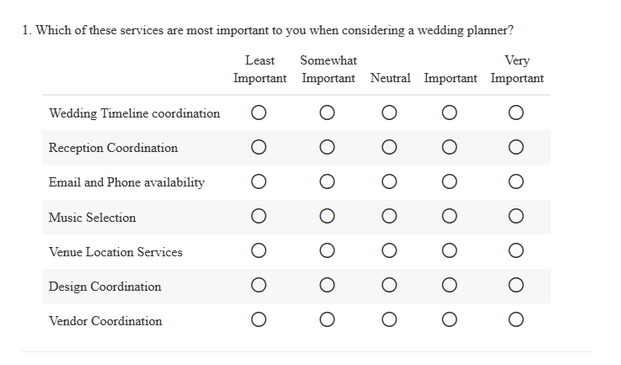
However, you want to avoid the problem of straightlining and you want to rank the relative importance of one service over another.
This is a perfect case for MaxDiff.
Coming to Terms With a New Question Type: MaxDiff
First, we need to define a few terms.
An attribute is an individual statement that you would like ranked. So if you were evaluating people’s color preferences, green might be an attribute.
A set is a group of attributes. You can decide the size and number of sets that will be displayed to the respondent. Green might be compared to red, blue, and yellow in a set.
The idea is that a set of attributes will be shown to the respondent, and they will have to choose the most and least important item in that set.
Essentially, MaxDiff questions force the respondents to make a choice.
Recommendations for Using MaxDiff
When choosing the number of attributes that will be displayed with each set, keep it five or less. When respondents have too many attributes to judge simultaneously they may feel overwhelmed.
If the attributes are displayed more than once in different sets, that will give you even better data.
Some attributes could be ranked again against a different set of attributes, which can garner more information about it’s relative importance against a wider range of options.
To illustrate, I had 7 attributes I wanted my respondents to rank about wedding planning services.
Each respondent will see 3 sets with 3 attributes per set. In this instance, at least 2 attributes could be displayed twice. Below is what one possible complete response looks like in this case:
You can see that “Wedding Timeline coordination” was in the first and second sets to be ranked. Likewise, “Email and Phone availability” was in the first and third sets.
The sets are randomly generated by the Alchemer system, so each respondent may not see every attribute depending on how many attributes are displayed and how many sets have been chosen to be shown each time.
If you show only two sets of three attributes, every respondent would not see every attribute in our example.
However over a larger number of respondents all of the sets would be shown a certain number of times.
If a particular set has been shown more frequently than another set over time with different respondents, it will be replaced with a less frequently viewed set.
Also, in the instructions for the question, I let the respondent know that they would be evaluating three sets of information and to click next to advance to the next set.
Finally, when building your survey keep in mind that MaxDiff questions should be placed alone on a page. This is because this question type uses the ‘next’ button to move to the next set of attributes to be ranked.
Doing the MaxDiff Math
Once you have your questions properly set up and your results are in, it’s time to look at the data.
MaxDiff questions report as a Bayesian Average. You can visit our help center for more information on all of the heavy mathematical lifting going on by our robots.
Below is an example report from the wedding planner survey:

In this example, the survey was completed several times. It’s clear that respondents tended to always rank “Vendor Coordination” as the most important attribute.
If you have 7 attributes as I did in the experiment, the highest possible score would be 7 and the lowest score would be 0. Likewise if you had 20 attributes, the highest score would be 20 and the lowest 0.
Why We Love MaxDiff
MaxDiff is a great way to find out the relative importance of a group of items.
The analysis of MaxDiff data can statistically support the preferences of respondents for brand names, attributes of a business, or statements about ideas.
MaxDiff gives us quick, statistically relevant feedback that avoids data contamination through straightlining. It’s a great question type that can serve you well!
You can learn more about MaxDiff through with a video walk through and more examples.
If you have already collected responses, and find that straightlining through various questions was an occasional problem, you can use our data cleaning tool to remove responses based on a threshold that you set.
We’ve used it ourselves on big market research projects, and it helped us eliminate irrelevant responses that could have seriously contaminated our data.