
One of the main sources of error in online surveys comes from sampling bias, which is simply having respondents that don’t accurately reflect the complete demographics of your target population.
You take a sample of the population and administer a survey, but the characteristics of those people are almost certainly not representative of the whole group. So if 45% of your customers are female, but only 30% of your respondents are female, you’ve got a sampling bias issue.
The problem gets even bigger when online surveys try to extrapolate their conclusions to the entire U.S. population, as a recent white paper from ResearchScape makes clear. Because a portion of the population never goes online at all, simply using online surveys creates an inherent sampling bias because, “repeated academic work reveals that non-internet users differ materially, socially, and psychologically from internet users.”
Sampling bias is a big hurdle, but it doesn’t have to stand between you and confident action on your survey data. Market researchers have come up with several tactics to combat sampling bias, and we’ll be looking into several of the most effective.
Probability Sampling: The Ideal Sampling Solution for Online Surveys
In an ideal world, we would have access to a complete list of the target population for our survey, which would let us use probability sampling to select respondents.
Probability sampling offers us an equal, random chance to select any single member of the population because we can contact them all. Obviously, this is extremely difficult to achieve.
Even massive retailers like Amazon, who have enormous databases on which to draw, can’t claim to have access to all ebook readers under 45 years old, or single moms who prefer to buy baby products online.
When we can’t reach everybody in our target audience with our survey invitations, there are a two alternatives we can pursue.
Online Panels and Convenience Sampling: The Next Best Things
By leveraging existing panels of people who are willing to take surveys and grabbing handy groups of respondents known as convenience samples, we can begin to approximate the reach of true probability sampling. Both of these have limitations, so we’ll also take a look at how we can adjust the survey data post-response to get better representativeness.
Using Probability Online Panels to Collect Responses
Many companies offer access to survey panels, large groups of people who have indicated that they’re willing to take surveys for a fee. Probability online panels are similar, but in these cases people are randomly selected to join the panel, generally through address-based sampling, and then relentlessly invited to participate until they agree.
If the respondents turn out not to have access to the internet, a computer, or a tablet, those items are provided.
This aspect of a probability online panel obviously makes it a much more expensive option than traditional online panels (Knowledge Networks estimates $900 per question for a sample size of 1,000).
Cost quickly turns probability panels into a non-viable option, and even probability sampling becomes too difficult when your survey is trying to reach markets with low-incidence populations. Many people turn to convenience samples in these situations.
Pros and Cons of Convenience Samples
Convenience samples are just what their name implies: convenient. Basically anyone who encounters the survey can take it, making it almost the exact opposite of probability sampling.
While certainly convenient, these types of surveys usually come with audience samples that aren’t very representative of the population as a whole.
If you send out your survey via social media looking for a convenience sample only, you’re clearly biasing the results toward users of social media.
Similarly, if you send out postcards inviting people to take the survey online, you’re skewing it toward people with internet access at home.
Even if you randomly select people from these groups to actually take the survey, you’re still not getting truly representative samples. As Jeffrey Henning, President of Resarchscape, points out, “A random sample of a convenience sample is still a convenience sample.”
“Fixing” Non-Probability Samples
There are two different ways that you can try to counteract the sampling bias inherent in a non-probability samples, one that you do after the survey is complete, and one that you use before collecting responses.
Some researchers think that you can counteract most of the sampling bias from convenience samples using these methods, but others argue that the way that responses were sampled can’t be overlooked. The important thing is to be aware of all the options available to you, and to identify the most rigorous method you can use based on your target audience, budget, and time.
Post-Stratification Weighting: The After Response Fix
This type of weighting takes place after you collect responses. Its goal is to make results conform more closely to the actual demographics of your target audience.
The simplest way to do this is with cell weighting, with which you group responses by demographic cell such as age and gender then calculate the weight of each cell so that it reflects the proportions of the target population:
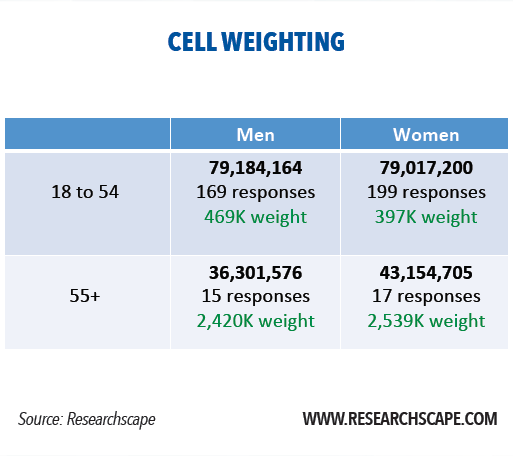
While it sounds like a simple math problem, weighting is actually a heavily editorial process. John Henning points out that 43% of surveys whose results were published in press releases were weight, “almost always by at least age, gender and geographic region. In such cases, responses are actually weighted differently for each configuration of age, gender and region.”
Cell weighting also assumes that we know the exact demographic makeup of our target audience so that we can assign accurate weights to each cell. This precise knowledge is rare, making most of this type of adjustment a “best guess” situation.
Furthermore, when we use weighting we’re assuming that, “the people we did survey in a particular demographic group are representative of the people that we did not survey. Yet this assumption is unlikely to hold true in many on-probability samples.”1
Raking Your Data For Accuracy
Since post-stratification cell weighting clearly has problems of its own, it’s steadily giving way to a new practice known as “raking.” This iterative process doesn’t require us to know the exact breakdown of our target market’s demographics.
John Henning explains raking as follows:
Raking…recalculates the weights [of cells] so that the weighted totals line up for one attribute in the target population. Raking repeats the process for a different attribute each cycle, taking the weights of its past output as the new input; the process repeats dozens of times until results converge for all weighted attributes when compared to the target population.1
While more labor-intensive than traditional weighting, raking can give you data that’s more representative of your audience’s actual makeup.
Find Your Respondents, Then Make the Data Work
Want to learn more about making your online surveys more representative? Read about how Researchscape automates SaaS workflows to improve customer satisfaction by clicking here.